
在这个科技高度发达的时代,百度已经成为人们能获取消息的主要途径。但如今的百度,到处充斥着一些重复的内容,对用户的访问造成很大的困扰。因此,百度需要对网页重复进行判断,对重复的网页,只选取一些高质量的我那工业,共用户浏览。然而,现有技术中一般是通过比较两个页面的内容和借点,来确认两个页面的相似度。
这种方法能够计算的比较准确,可时间复杂度太高,计算很费时间。通过对一个页面中的某些重要信息进行签名,然后比较两个页面的签名,来计算相似度,这种方式比较简单高效,计算速度比较快,比较适合百度这种海量信息的应用场景。
1,网站重复内容的判断
A,获取多个网页;
B,分别提取网页的网页正文;
C,从网页正文中提取一个或多个句子,并根据一个或多个句子计算网页正文句子签名;
D,根据网页正文句子签名对多个网页进行聚类;
E,针对每一类下的网页,计算网页的附加签名;
F,根据附加签名判断每一类下的网页是否重复。
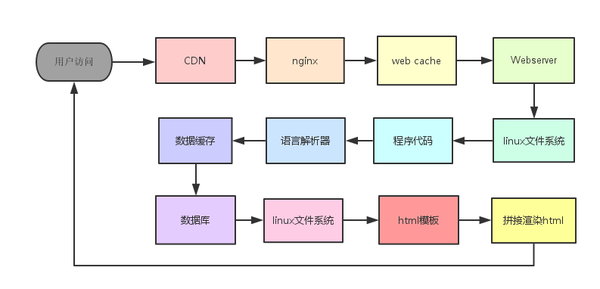
网站页面基本架构
提取正文
A,对网页进行分块;
B,对分块后的网页进行块过滤,以获取包含网页正文的内容快;
C,从内容块中提取网页正文。
正文分句
A,对网页正文进行分句;
在本步骤中,可利用分号,句号,感叹号等表示句子完结的标志符号来对网页正文进行分句。此外,还可以通过网页正文的视觉信息来对网页正文进行分句。
B,对分句后的网页正文进行过滤及转换;
在步骤中,先过滤掉句子中的数字信息;版权信息以及其他对网页重复判断不起决定性作用的信息。随后,对句子进行转换,例如,进行全角/半角转换或者繁体/简体转换,以使得转换后的句子的格式统一。
C,从过滤及转换后的网页正文中提取长的一个或多个句子;
在本步骤中,过滤及转换后的网页正文提取出长的一个句子或者做场的预定数量连续句子的组合。例如,某个网页实例中,经过过滤及转换后的某段长,远超其他句子,因此可选择该段为网页正文句子,或者选择长的连续句子组合作为网页正文句子。
D,对一个或多个句子进行hash签名运算,以获取网页正文句子签名。
simhash算法就是比较各网页的附加签名是否相同或相似来判断网页是否重复。具体来说,在比较利用simhash签名运算获得的网页正文签名时,比较网页正文签名的不同位数,不同位越少,表示网页重复的可能性越高,在比较其他的附加签名时,若附加签名相等,表示网页在该纬度上重复。
总结:
1、两个网页的真实标题签名相同。
2、两个我那工业的网页内容签名相同。
3、两个网页的网页正文签名的不同位数小于6.。
4、两个网页的网页位置签名相同,并且url文件名签名相同。
5、评论块签名、资源签名、标签标题签名、摘要签名、url文件名签名中有三个签名相同。
附加信息整站判断重复标准:















 联系建站公司
联系建站公司